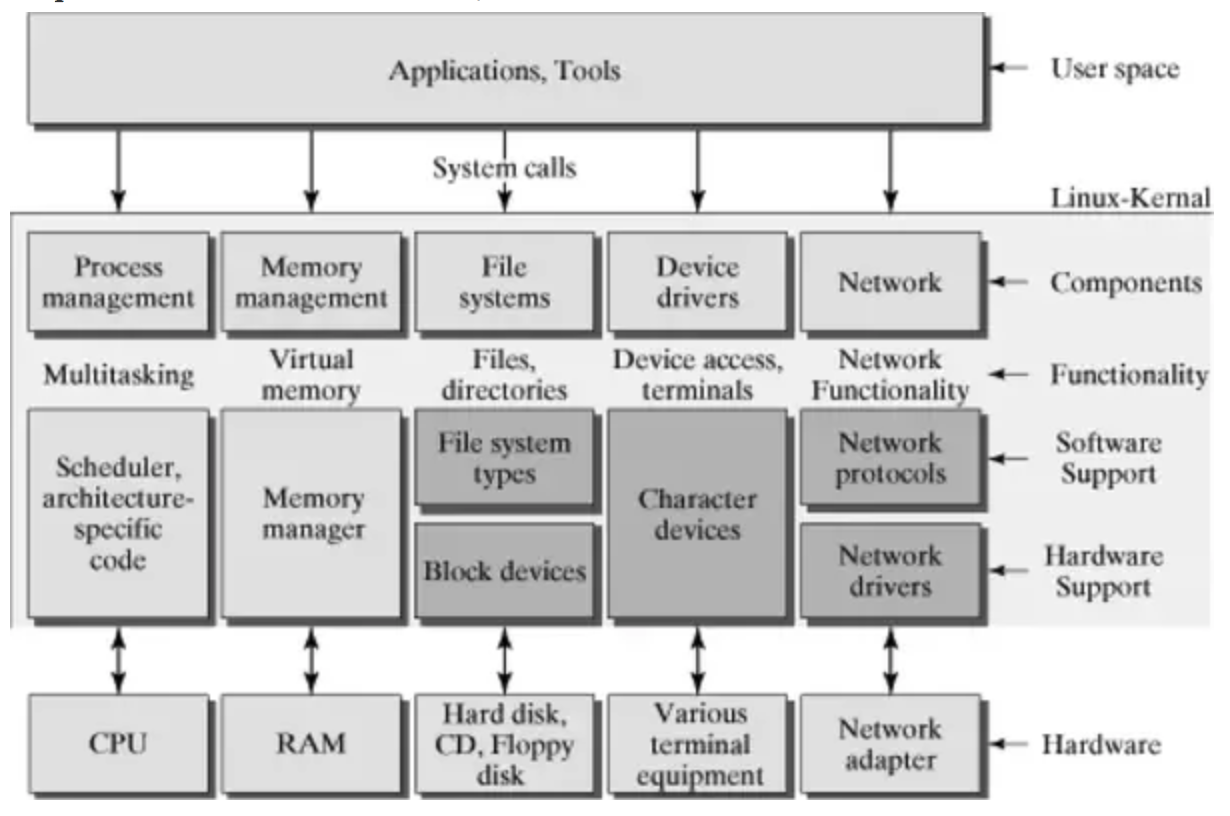
System Calls : The kernel exposes a number of IO system calls which has a corresponding system call handler.The system call handler, which has a structure similar to that of the other exception handlers, performs the following operations:
- Saves the contents of most registers in the Kernel Mode stack (this operation is common to all system calls and is coded in assembly language).
- Handles the system call by invoking a corresponding function called the system call service routine.
- Exits from the handler: the registers are loaded with the values saved in the Kernel Mode stack, and the CPU is switched back from Kernel Mode to User Mode (this operation is common to all system calls and is coded in assembly language). To associate each system call number with its corresponding service routine, the kernel uses a system call dispatch table, which is stored in the sys_call_table array and has NR_syscalls entries (289 in the Linux 2.6.11 kernel). The n th entry contains the service routine address of the system call having number n.
- The Northbridge[ memory controller hub] typically handles communications among the CPU, RAM, BIOS ROM, and PCI Express (or AGP) video cards, and the Southbridge.
- The southbridge [Input/Output Controller Hub ],The Southbridge typically implements the “slower” capabilities of the motherboard. The Southbridge can usually be distinguished from the Northbridge by not being directly connected to the CPU. Rather, the Northbridge ties the Southbridge to the CPU. Through the use of controller integrated channel circuitry, the Northbridge can directly link signals from the I/O units to the CPU for data control and access.
- North and south bridge refer to the data channels to the CPU, memory and Hard disk data goes to CPU using the Northbridge. And the mouse, keyboard, CD ROM external data flows to the CPU using the Southbridge. However in the recent architectures, the functionality previously provided by the North Bridge has now been integrated into the CPU.
- ISA - Industry Standard Architecture
- EISA - Extended Industry Standard Architecture
- MCA - Micro Channel Architecture
- VESA - Video Electronics Standards Association
- PCI - Peripheral Component Interconnect
- PCI Express (PCI-X)
- PCMCIA - Personal Computer Memory Card Industry Association (Also called PC bus)
- AGP - Accelerated Graphics Port
- SCSI - Small Computer Systems Interface.
- USB - Universal serial bus
IO Devices addressing
There are 2 ways in which IO Devices addressing is done
- Memory mapped IO
- Port mapped IO
Memory Mapped:
- address space is shared between Memory and IO
- I/O devices are mapped into the system memory map along with RAM and ROM. To access a hardware device, simply read or write to those ‘special’ addresses using the normal memory access instructions.
- Same instructions for transferring data to memory and IO
- The advantage to this method is that every instruction which can access memory can be used to manipulate an I/O device.
- The disadvantage to this method is that the entire address bus must be fully decoded for every device. For example, a machine with a 32-bit address bus would require logic gates to resolve the state of all 32 address lines to properly decode the specific address of any device. This increases the cost of adding hardware to the machine which would result in complex architecture.
Port mapped IO
- I/O devices are mapped into a separate address space. This is usually accomplished by having a different set of signal lines to indicate a memory access versus a device access. The address lines are usually shared between the two address spaces, but less of them are used for accessing ports. An example of this is the standard PC which uses 16 bits of port address space, but 32 bits of memory address space.
- The advantage to this system is that less logic is needed to decode a discrete address and therefore less cost to add hardware devices to a machine.To read or write from a hardware device, special port I/O instructions are used.
- From a software perspective, this is a slight disadvantage because more instructions are required to accomplish the same task. For instance, if we wanted to test one bit on a memory mapped port, there is a single instruction to test a bit in memory, but for ports we must read the data into a register, then test the bit.
CPU and DMA addresses
There are several kinds of addresses involved in the DMA API, and it’s important to understand the differences.
The kernel normally uses virtual addresses. Any address returned by kmalloc(), vmalloc(), and similar interfaces is a virtual address.
The virtual memory system (TLB, page tables, etc.) translates virtual addresses to CPU physical addresses. The kernel manages device resources like registers as physical addresses. These are the addresses in /proc/iomem. The physical address is not directly useful to a driver; it must use ioremap() to map the space and produce a virtual address.
I/O devices use a third kind of address: a “bus address”. If a device has registers at an MMIO address, or if it performs DMA to read or write system memory, the addresses used by the device are bus addresses. In some systems, bus addresses are identical to CPU physical addresses, but in general they are not. IOMMUs and host bridges can produce arbitrary mappings between physical and bus addresses.
From a device’s point of view, DMA uses the bus address space, but it may be restricted to a subset of that space. For example, even if a system supports 64-bit addresses for main memory and PCI BARs, it may use an IOMMU so devices only need to use 32-bit DMA addresses.
Here’s a picture and some examples::
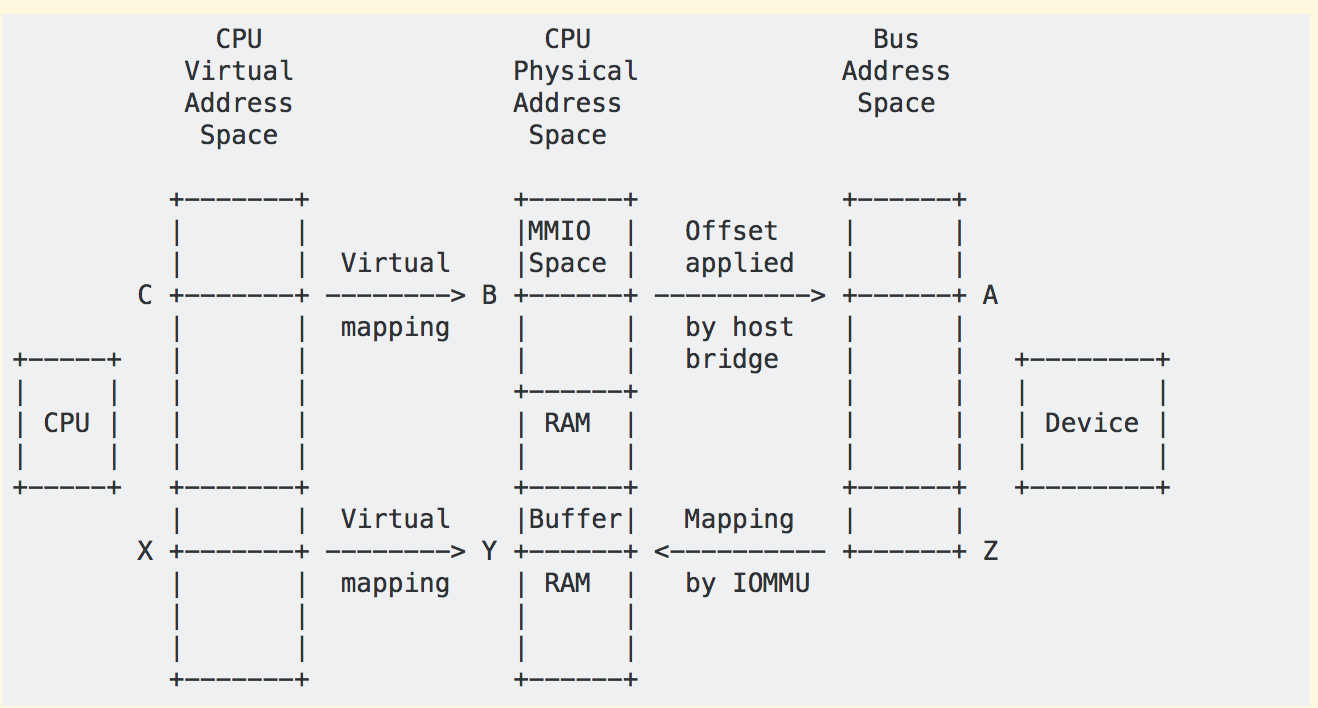
During the enumeration process, the kernel learns about I/O devices and their MMIO space and the host bridges that connect them to the system. For example, if a PCI device has a BAR, the kernel reads the bus address (A) from the BAR and converts it to a CPU physical address (B). The address B is stored in a struct resource and usually exposed via /proc/iomem. When a driver claims a device, it typically uses ioremap() to map physical address B at a virtual address (C). It can then use, e.g., ioread32(C), to access the device registers at bus address A.
If the device supports DMA, the driver sets up a buffer using kmalloc() or a similar interface, which returns a virtual address (X). The virtual memory system maps X to a physical address (Y) in system RAM. The driver can use virtual address X to access the buffer, but the device itself cannot because DMA doesn’t go through the CPU virtual memory system.
In some simple systems, the device can do DMA directly to physical address Y. But in many others, there is IOMMU hardware that translates DMA addresses to physical addresses, e.g., it translates Z to Y. This is part of the reason for the DMA API: the driver can give a virtual address X to an interface like dma_map_single(), which sets up any required IOMMU mapping and returns the DMA address Z. The driver then tells the device to do DMA to Z, and the IOMMU maps it to the buffer at address Y in system RAM.
Application Buffering , page cache , Memory mapped IO , DirectIO
Application Buffering or User Space Buffering
First a buffer space is allocated in the user space, and the reference of this buffer is passed to the syscall fread().
- For read operation, first the page cache [kernel buffer] is checked. if it is available it is copied to the buffer in the user space.
- If the data is not available in the page cache, the data is fetched from the IO device and cached in the page cache before coping to the buffer in user space.
- The data is written to the page cache [kernel buffer] and marked as dirty and the write is succeeded. Periodically the dirty pages are synced to the file. However we can manually trigger this sync using fsync() system call.
The three types of buffering available are unbuffered, block buffered, and line buffered.
- When an output stream is unbuffered, information appears on the destination file or terminal as soon as written;
- when it is block buffered many characters are saved up and written as a block;
- when it is line buffered characters are saved up until a newline is output or input is read from any stream attached to a terminal device(typically stdin)
Page caches
The IO data is stored in 2 places once in page cache and again in user space buffer.One key thing to notice is that, Pages marked dirty will be flushed to disk as since their cached representation is now different from the one on disk. This process is called writeback. writeback might have potential drawbacks, such as queuing up IO requests, so it’s worth understanding thresholds and ratios that used for writeback when it’s in use and check queue depths to make sure you can avoid throttling and high latencies.
- Page Cache facilitates temoporal and spatial locality principles which means recently accessed and closely located data are accessed more often.
- Page Cache also improves IO performance by delaying writes and coalescing adjacent reads.
- Since all IO operations are happening through Page Cache, operations sequences such as read-write-read can be served from memory, without subsequent disk accesses
Direct IO
With The direct IO, the intermediate page cache or the kernel buffer is eliminated and the application interacts directly with the device. Directly here means it still invlovves kernel for IO interactions. Only catch here is that the kernel reads/writes data immediately to the device.
- This might result into performance degradation, since the Kernel buffers and caches the writes, allowing for sharing the cache contents between application. When used well, can result in major performance gains and improved memory usage.
- Developers can ensure fine-grained control over the data access , possibly using a custom IO Scheduler and an application-specific Buffer Cache.
- Because Direct IO involves direct access to backing store, bypassing intermediate buffers in Page Cache, it is required that all operations are aligned to sector boundary.When using Page Cache, because writes first go to memory, alignment is not important: when actual block device write is performed, Kernel will make sure to split the page into parts of the right size and perform aligned writes towards hardware.
- Whether or not O_DIRECT flag is used, it is always a good idea to make sure your reads and writes are block aligned. Crossing segment boundary will cause multiple sectors to be loaded from (or written back on) disk.
Memory mapped IO (mmap)
With mmap, the page cache is mapped directly to the user space buffer, avoiding additional copying from page cache to user space buffer.
- mmap file can be in private mode or shared mode.Private mapping allows reading from the file, but any write would trigger copy-on-write of the page in question in order to leave the original page intact and keep the changes private, so none of the changes will get reflected on the file itself. In shared mode, the file mapping is shared with other processes so they can see updates to the mapped memory segment.
- Unless specified otherwise, file contents are not loaded into memory right away, but in a lazy manner. Space required for the memory mapping is reserved, but is not allocated right away. The first read or write operation results in a page-fault, triggering the allocation of the appropriate page. By passing MAP_POPULATE it is possible to pre-fault the mapped area and force a file read-ahead.
- It’s also possible to map a file into memory with protection flags (for example, in a read-only mode). If an operation on the mapped memory segment violates the requested protection, a Segmentation Fault is issued.
Final thoughts
We started off with highlighting different hardware and software components that make IO possible. Later we discussed the different ways of addressing IO devices. Later we concluded with different ways IO is done.
References
- Linux Device Drivers, 3rd edition
- Understanding Linux Kernel
- DMA
- IO,pagecache
- linux man page
Related posts
- 19 May 2024
- Resiliency Matrix for Cloud Native applications 24 Mar 2022
- Multi Region/Multi cluster Cache replication 12 Jul 2021